翻訳メモリの操作はプロジェクトの翻訳メモリから行います。
あらかじめ設定されている翻訳メモリの設定は変更しないよう注意してください。
翻訳/校正に使いたい自作の翻訳メモリがある場合、プロジェクトに設定すると利用できます。
1. 翻訳メモリ画面を開く
1) プロジェクトの左メニューの[翻訳メモリ]をクリックします。
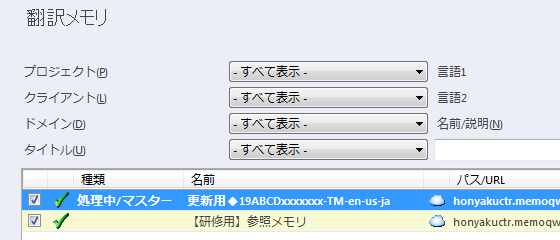
2) あらかじめプロジェクトに設定してある翻訳メモリの一覧が表示されます。既存の設定は変更しないように注意してください。特に「種類」欄はクリックするだけで設定が変わってしまいますので、翻訳メモリを選択するときは「名前」欄などをクリックするようにしてください。
2. 自作の翻訳メモリを利用する
翻訳/校正に使いたい自作の翻訳メモリをプロジェクトに設定して利用します。
翻訳メモリの保存場所がマイコンピュータであれば、他のプロジェクト関係者には表示されません。
2-1. 翻訳メモリの新規作成
1) [翻訳メモリ]タブの[新規作成/使用]をクリックします。

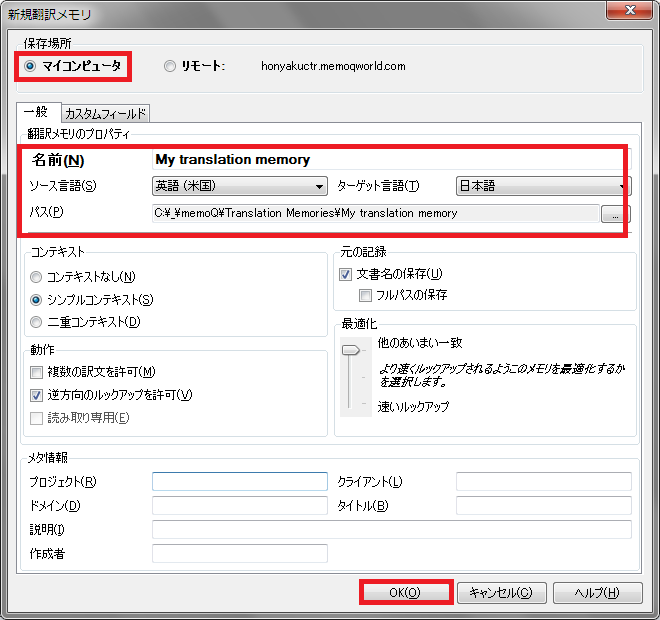
2) 保存場所は「マイコンピュータ」を選択し、[一般]タブで名前と言語、パスを設定します。
他の項目は必要に応じて編集し、[OK]をクリックします。
3) 翻訳メモリが作成されました。翻訳メモリのアイコンがPCであることを確認します。
もしアイコンが雲の場合はサーバー上に作成されているので、「名前」欄を右クリックして削除してから作成し直します。「種類」欄をクリックすると設定が変わってしまうので注意してください。

2-2. 翻訳メモリへのデータインポート
1) データをインポートしたい翻訳メモリの「名前」欄をクリックして反転させます。
「種類」欄をクリックすると設定が変わってしまうので注意してください。

2) [翻訳メモリ]タブの[TMX/CSVからインポート]をクリックします。

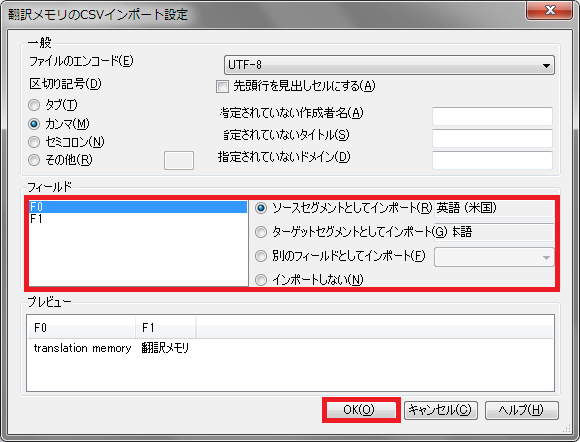
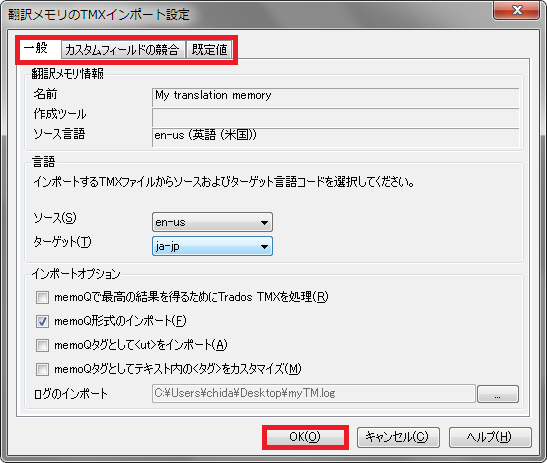
3) インポートするファイルを指定後、表示された画面で必要な設定を行い[OK]をクリックします。
CSVファイルの場合は、各フィールドの設定を忘れずに行います。
TMXファイルの場合は、タブが複数あるので確認するようにします。
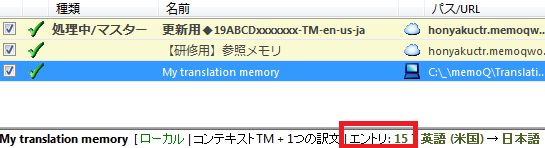
4) インポート中の画面が消えるとインポート完了です。エントリ数などを確認します。
2-3. 翻訳メモリの編集
(詳細はmemoQ Documentation – Edit a translation memory参照)
1) データを編集したい翻訳メモリの「名前」欄をクリックして反転させます。
「種類」欄をクリックすると設定が変わってしまうので注意してください。

2) [翻訳メモリ]タブの[編集]をクリックします。

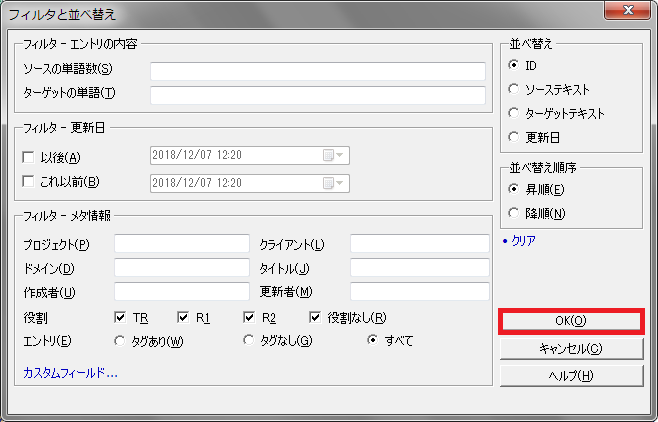
3) フィルターと並べ替えの設定画面が表示されます。必要に応じてデータの表示条件を指定します。翻訳メモリに登録されているすべてのデータを表示したいときは、フィルターの設定は不要です。設定が終わったら[OK]をクリックします。
4) プロジェクトに翻訳メモリのタブが開きます。
編集した内容を保存するには、[翻訳メモリエディタ]タブの[変更の保存]をクリックします。
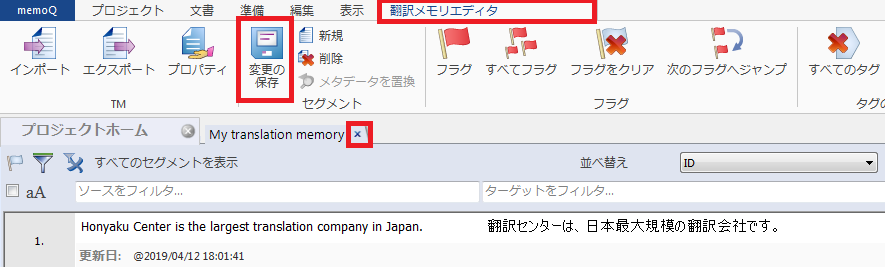
5) 編集が終わったら、タブの閉じるマーク![]() をクリックして閉じます。
をクリックして閉じます。
2-4. 翻訳メモリのデータエクスポート
1) データをエクスポートしたい翻訳メモリの「名前」欄をクリックして反転させます。
「種類」欄をクリックすると設定が変わってしまうので注意してください。

2) [翻訳メモリ]タブの[TMXにエクスポート]をクリックします。

3) 保存場所を指定して保存します。
3. 翻訳メモリの更新
文書から、特定の条件に合致するデータだけを翻訳メモリに登録することができます。
1) 翻訳メモリを更新するための訳文が入力されている文書を選択し、[準備]タブの[確定して更新]をクリックします。
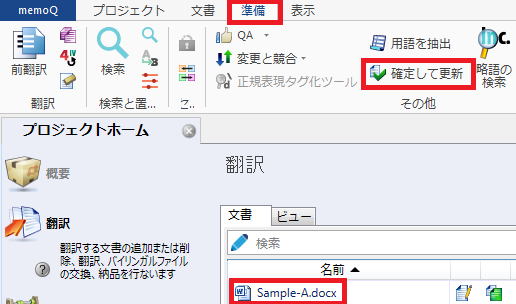
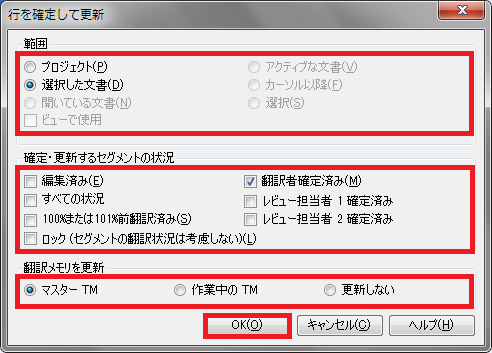
2) 範囲、セグメントの状況、更新対象のメモリを設定し、[OK]をクリックします。
3) 更新が終わると結果が表示されます。確認して[閉じる]をクリックします。
4. 翻訳メモリの詳細
memoQでの翻訳メモリの設定の詳細は下記の通りです。新規作成時にのみ設定できる項目もあります。
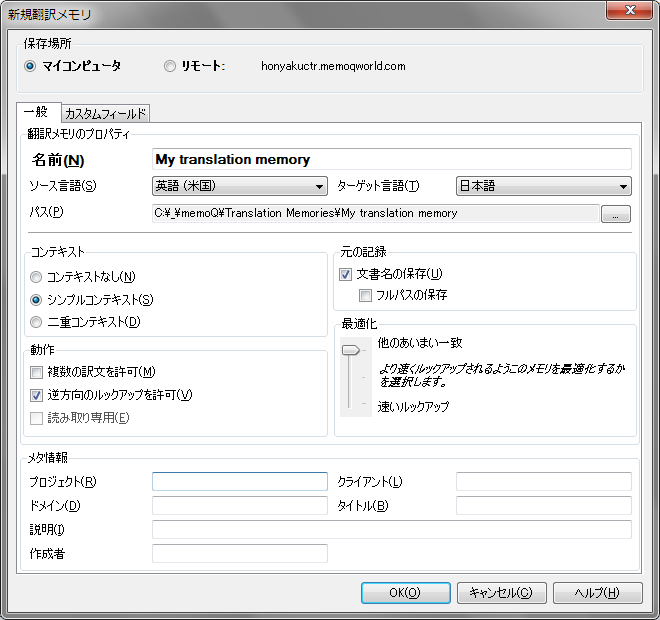
4-1. コンテキスト <新規作成時のみ設定可能>
コンテキストなし : 作業セグメントのみを記録。一致した場合、100%マッチとなる。
シンプルコンテキスト : 作業セグメントとその前後のセグメントを記録。一致した場合、101%マッチとなる。
二重コンテキスト : XMLなどの原文ファイルでセグメントに独自のID番号が必要。作業セグメントとその前後のセグメント、およびID番号を記録。一致した場合、102%マッチとなる。
4-2. 動作 <新規作成時のみ設定可能>
複数の訳文を許可 : セグメントを確定するたびに新しい翻訳ユニットを作成。重複エントリーが生じるため、メンテナンスの実施を推奨。
逆方向のルックアップを許可 : 言語方向が異なる翻訳メモリを参照。更新は不可。
読み取り専用 : 設定不可。
4-3. 最適化
動作が遅い場合のみ変更します。
4-4. メタ情報
翻訳メモリ自体のメタ情報として使用されます。
翻訳メモリに保存される各セグメントのメタ情報はプロジェクトから取得されます。 [カスタムフィールド]タブでメタ情報をカスタマイズして追加することも可能ですが、他ツールとの互換性がないことがあります。