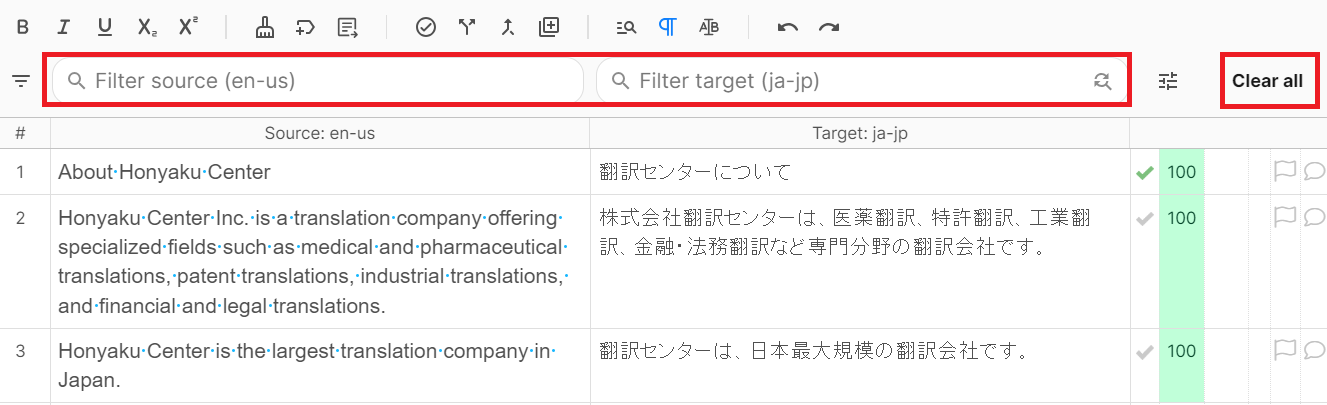
原文・訳文欄の上にあるボックスに文字をいれると、原文・訳文欄それぞれを検索し、該当セグメントのみが抽出されます。
あるセグメント (分節)・言い回しが記述された箇所を一括で確認したい場合などに便利です。
[Clear all] ボタンをクリックすると、フィルタが消去され、通常どおりの表示となります。
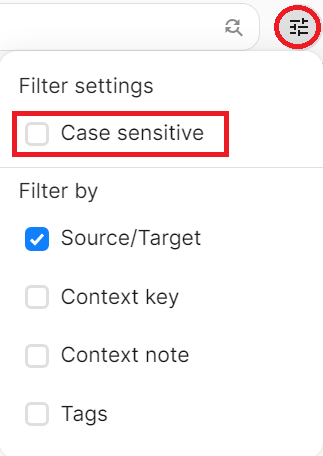
なお、フィルターオプションボタン ![]() をクリックし、 [Case sensitive] にチェックをいれると、大文字と小文字を区別して検索します。
をクリックし、 [Case sensitive] にチェックをいれると、大文字と小文字を区別して検索します。
また、左側の ![]() をクリックすると、次のようなオプションボックスがでてきます。
をクリックすると、次のようなオプションボックスがでてきます。
各 ![]() マークをクリックすると、右図のようなメニューが展開されます。
マークをクリックすると、右図のようなメニューが展開されます。
項目にチェックをいれることで、該当する部分のみを抽出することができます。
フィルタを解除する場合は、右横の [Clear all] ボタンをクリックしてください。
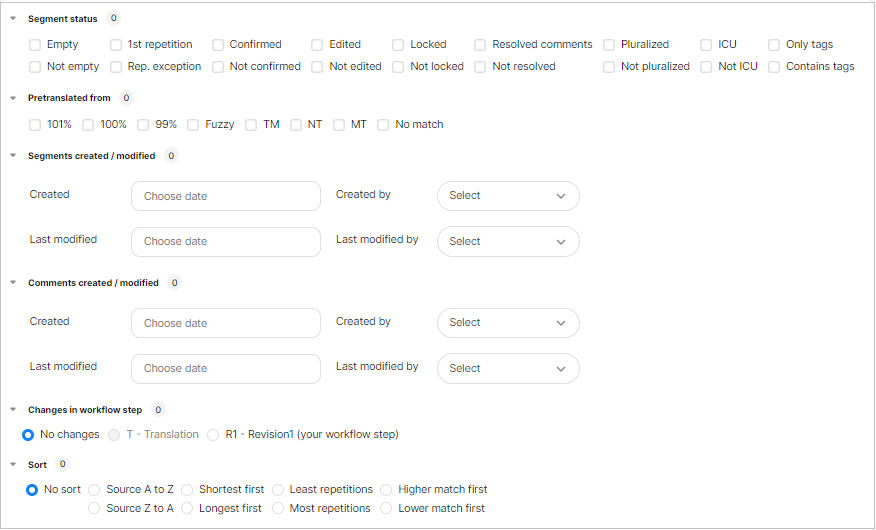
【Segment Status】:分節のステータスによって抽出することができます。
Empty(空欄)/Not empty(空欄以外)
1st repetition(繰り返しの初出)/Rep.exception(繰り返しの例外)
Confirmed(確定済み)/Not confirmed(未確定)
Edited(編集済み)/Not edited(未編集)
Locked(ロック済み)/Not locked(ロック済み以外)
Resolved comments(解決済みのコメント)/Not resolved(未解決のコメント)
Pluralized(複数形の使用)/Not pluralized(複数形の不使用)
Only tags(タグだけのセグメント)/Contains tags(タグを含むセグメント)
便利なものとしては、「Empty」(訳文が空欄)、「Not Confirmed」(未確定箇所)、「1st Repetition」(繰り返しがある場合、最初にでてきた分節のみ抽出)があげられます。
【Pretranslated from】:前翻訳に何をいれたかで抽出することができます。
101%/100%/Fuzzy(あいまい一致)/TM(翻訳メモリ)/NT(翻訳不要箇所)/MT(機械翻訳)/No match(一致なし)
「Fuzzy」にチェックをいれると、翻訳メモリとのファジーマッチ箇所のみのセグメントを抽出したりすることができます。
*すでに前翻訳が入っていることが前提となります。
【Segments created/modified】:セグメントの作成日/更新日(Revision以降のフローで利用できます)
最初に作業を行った人の内部ID・日にち、修正を行った人の内部ID・日にちによって、セグメント抽出することができます。
【Comments created/modified】:コメントの作成日/更新日(Revision以降のフローで利用できます)
コメントを入力した人の内部ID・日にち、修正を行った人の内部ID・日にちによって、セグメント抽出することができます。
【Changes in workflow step】:ワークフローステップの変更
No Changes(変更なし)/T-Translation/R1-Revison1・・・・
ご自身の担当のステップを選択すると、編集作業(変更)したセグメントだけ抽出することができます。
【Sort】:並べ替え
Source A to Z(原文をA-Z順)/Source Z to A(原文をZ-A順)
Shortest first(原文の長さ(昇順))/Longest first(原文の長さ(降順))
Least repetitions(繰り返しの少ないセグメント)/Most repetitions(繰り返しの多いセグメント)
Higher match first(一致率の高い順)/Lower match first(一致率の低い順)
アルファベット・文章の長さ・繰り返しの多さ、一致率の高さを並べ替えることができます。